
推荐系统中的评测大致分为三类:离线评测、在线评测、用户调研。在线评测通常将流量随机分配到不同策略下下比较不同策略的优劣(又称A/B test或bucket test),操作简单,效果准确直观,但代价昂贵,可能伤害部分用户的体验;离线评测使用模拟器模拟线上环境获取结果,对线上几乎没有影响,因此一些重要系统通常要先通过离线评测确保算法效果再上线进行对比,但由于离线评测经常引入model bias及partial label(新算法产生的结果在线上真实环境下未被展示)等问题,使得线下评估结果与线上不一致;用户调研代价昂贵切过于主观,个人认为比较适用于产品调研,不适用于算法效果评估。这其中离线评测一直是推荐系统较为关注的话题,如何保持离线评测与在线评测结果的一致性在众多推荐系统中都是亟待解决的问题。
A Comparison of Offline Evaluations, Online Evaluations, and User Studies in the Context of Research-Paper Recommender Systems
在论文推荐数据集上对比了user study、online evaluations和offline evaluations三种评测方法。
实验方法
- 将用户在mind-map中引用的论文作为ground-truth
- 从数据集中移除最近添加的一篇paper作为训练集,观察推荐的结果是否能够命中这篇移除的paper作为离线评测指标(
success@K); - 观察不同算法和参数在三种评测方法下的各种指标。
实验结果
- 假设user study的评测是准确的,通过计算评测指标之间的Pearson相关性,据此判断online evaluation和offline evaluation的准确性
- 在某些指标上,离线评测的相对大小关系与在线评测和user study一致,但绝对值差异较大
- 离线评测无法评估展示差异、用户意图等因素的影响
结论
- 在线指标中UCTR比CTR更能反应用户对推荐结果的满意度(CTR/UCTR高以为了增加了决策成本)
- When incomplete or even biased datasets are used as ground-truth, recommender systems are evaluated based on how well they can calculate such an imperfect ground-truth.
Offline and Online Evaluation of News Recommender Systems at swissinfo.ch (Recsys 2014)
以新闻推荐为例对比了不同算法在离线评估和在线评估阶段的差异,并对比了在线实验中CTR和准确率的差异。
实验方法
- Context Trees (CT):根据用户的浏览序列构造树,每个节点都是一个context,每个context下都有特定的预测模型,融合多种策略。热门、随机策略作为baseline,选用baseline策略最优下的参数。
- 选用
success@3(无论下一次点击是来自推荐还是其他地方)作为在离线评测指标 - 选用
success@3和CTR(推荐结果点击率)作为在线评测指标
实验结果
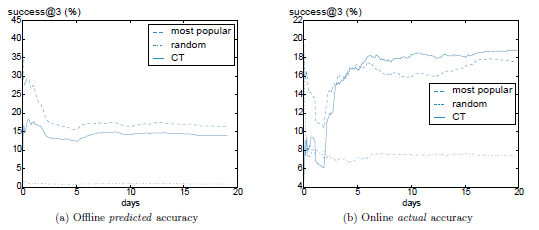
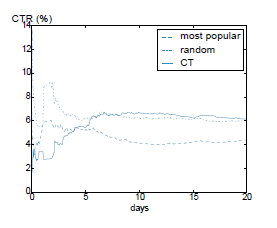
- 热门策略线上CTR4%, 准确率由16.5%提高至17.5%,因此3/4的点击来自于其他地方
- CT策略线上CTR6%, 准确率由14%提高至19%,1/6的点击来自于其他地方,因此价值更高
- 随机策略线上点击率较高是因为多数用户历史行为较少个性化效果不明显;在行为较多的用户中,随机与CT的CTR差异会被拉大
- 热门策略线上CTR低是因为用户在看到推荐之前已经在网页上方看过了热门的新闻
结论
- offine evaluations of accuracy are not always meaningful for predicting the relative performance of different techniques.
- CTR overestimates the actual impact for popular items, and thus gives a skewed impression of the actual performance
- CTR might not be the optimal metric for online evaluation, because some of the clicks are for popular items that people would have chosen anyway.用推荐的准确率更能体现推荐带来的增量收益
- 离线评估可以会引入其他模块带来的影响(热门策略与推荐位上方的头条模块)
2.消除离线评估的Bias
Reducing Offline Evaluation Bias in Recommendation System
作者将bias归因为:随时间推移item的概率分布是变化的(可能是线上推荐系统造成的影响),因此如果是均匀采样则无法在两个不同的时间点评估不同的算法。借用covariate shift的思想,通过学习的方法求得一组变量控制采样,使得t1时刻item的分布尽量逼近t0时刻,从而降低bias。
Defination
离线评测通常是按一定概率分布选取一个user(通常是考虑每个用户的商业价值),再以一定概率选取一个item,并把该item从数据集中刨除,在该状态下为user推荐k个item,通过观察是否命中评估推荐算法,如(1)。这个评估函数应该是与时间无关的才能保证离线评测的稳定性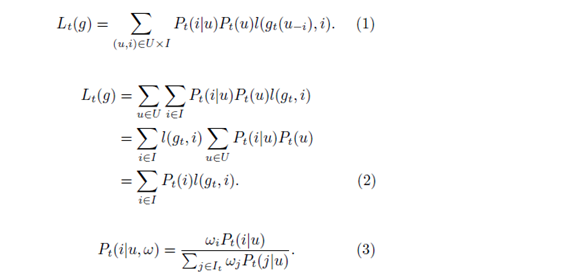
简化问题:假设算法每次推荐结果是固定的,则只有item的概率分布影响评测的稳定性,如(2)。解决方法有两种:
- 记录t0时刻item的分布,在t1时刻沿用这个分布选择item再选取user。但这和离线评测流程是相悖的(先选择user在选择item),且无法响应新的user和item
- 更好的方法是借鉴covariate shift的思想,给定一个user引起一组变量
w控制item选取,如(3),使得Pt1(i|w) ~ Pt0(i)(目标函数)
Solution & Result
优化w看以看做是最小化两个分布之间的差异,根据Kullback-Leibler divergence的定义,两者之间的差异主要取决于出现频率最高的item,因此为了提高计算效率,只选择t0和t1之间变化最大的p个item求解w
使用Viadeo(类似于linkedin)技能tag推荐数据集,为了更加直观的观察weighting策略的影响,这里依然选用了两个Constant Algorithm,算法1总是推荐评测阶段推荐最多的5个item给用户,算法2总是推荐历史上评测阶段没有推荐过但之前推荐最多的5个item给用户。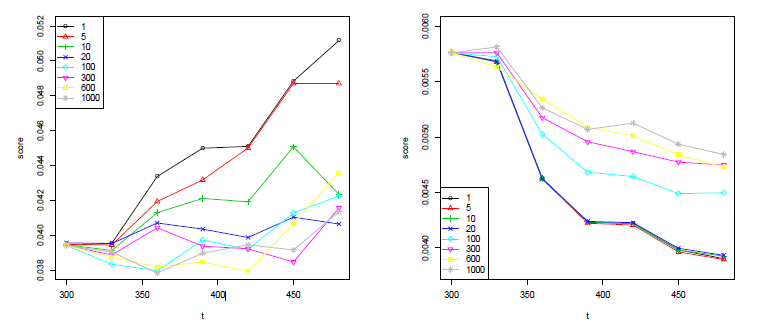
As both algorithms are constant, it would be reasonable to expect minimal variations of their offine evaluation scores. However in practice the estimated quality of g1 increases by more than 25 %, while the relative decrease of g2 reaches 33 %.
随着weighting策略的引入,离线评测的误差得到矫正,g1在p=20是趋于收敛。g2收敛速度和误差相对不太理想(why?)
Comments
在特定数据集和特定方法上通过对item采样时引入weighting策略解决了不同时间之间的bias,covariate shift的思想值得借鉴,但是数据集和方法都有局限性:文中只给出了constant algorithm上的解决方法,但在实际使用的算法上并没有可行的solution;实验中提到的两个时间点对推荐系统做了重大改变,且推荐系统对tag点击影响巨大,这种分布的变化和假设并不适用于其他数据集,该方法的通用性有待考察。
Unbiased Offline Evaluation of Contextual-bandit-based News Article Recommendation Algorithms(WSDM 2011)
针对新闻推荐中的bandit算法提出了基于replay方法的离线评估,保证离线评测是unbiased,并证明了采样的复杂度。
contexual bandit problem
multi-armed bandit problem是对EE问题(exploit:利用已知短期利益最大化,explore探索未知长期利益最大化)的建模。在新闻推荐中,每篇新闻可以看做一个arm,每次根据preceding interactions和current context选择一个arm作为推荐结果,如果推荐结果被点击了则payoff为1否则为0。对一篇新闻payoff的期望等同于它的CTR,选择CTR最高的新闻等同于最大化bandit问题中的payoff。
Unbiased offline evaluation
假设(1)the individual events are i.i.d.; (2)the logging policy chose each arm at each time step uniformly at random;(3)K constant arm Set。则可以证明evaluating the policy against T real-world events from D is equivalent to evaluating the policy using the policy evaluator on a stream of logged events。基于这个结论给出了两个离线评测的算法:
通过重复算法1然后平均每次的误差可以准确的评测算法A;同样可以证明随着L的增大,算法2的误差也会在线性时间内收敛(K趋近于L/K)。
Result & Comments
线上分了两个桶:random bucket和serving bucket,离线用random bucket的Event和serving bucket的Algorithm做评测,得出结论:展现次数大于2w的文章,在线和离线的CTR基本一致,因此离线评测是unbiased。
But,从随机桶里取数据本身就消除了model bias的问题,如何unbiased说明是policy evaluator的功劳?而且线上一直留着一个随机桶feasible吗?
Related Work
作者一年后在JMLR上发表了An Unbiased Offline Evaluation of Contextual Bandit Algorithms with Generalized Linear Models, 依然是从Yahoo新闻推荐的random bucket里抽取了数据,比较了linear、logistic和probit三种线性模型,以及ε-greedy和UCB两种exploration策略的效果,离线评测部分没有新内容。
3.总结
离线评估系统一直为完美主义者所青睐,各路学者也一直在讨论,但大多集中在概念上,并没有可以立即转化为生产力的实现;少有的几篇关于如何消除bias的paper前提假设过强,并不能广泛推广到实际情景中。虽然达到完全消除离线评估bias的目标仍很遥远,但已有的工作对何如减小bias仍有很多启迪。工业界精准的评测仍以在线评估为主,离线评测即使作为辅助手段也仍有很远的路要走,需要具体问题具体分析,短时间内很难达成一致的框架。