
1 介绍
信息量太大回头再写。。
# 一天后更新
不想写了差不多就下面这些内容吧。。
2 背景
2.1 fuzzing流程

fuzzing的核心算法
initSeedCorpus:初始化新的输入
isDone:决定fuzzing是否停止
choose:从队列中选择至少一个种子输入进行变异
mutate:从至少一个种子输入和观察到的现象中产生新的候选种子
eval:评价程序的种子产生观察现象
isInteresting:根据观察到的现象决定种子是否保留
fuzzer的最终目标是生成输入使程序crash。其他类型的观察现象也是需要的,比如用例运行的时间,可以用来指示算法复杂度漏洞的存在。
2.2 近年来fuzzing的进展
本文研究对象是2012至2018这7年顶会上32篇相关论文。其中25篇是2016年以来的成果。
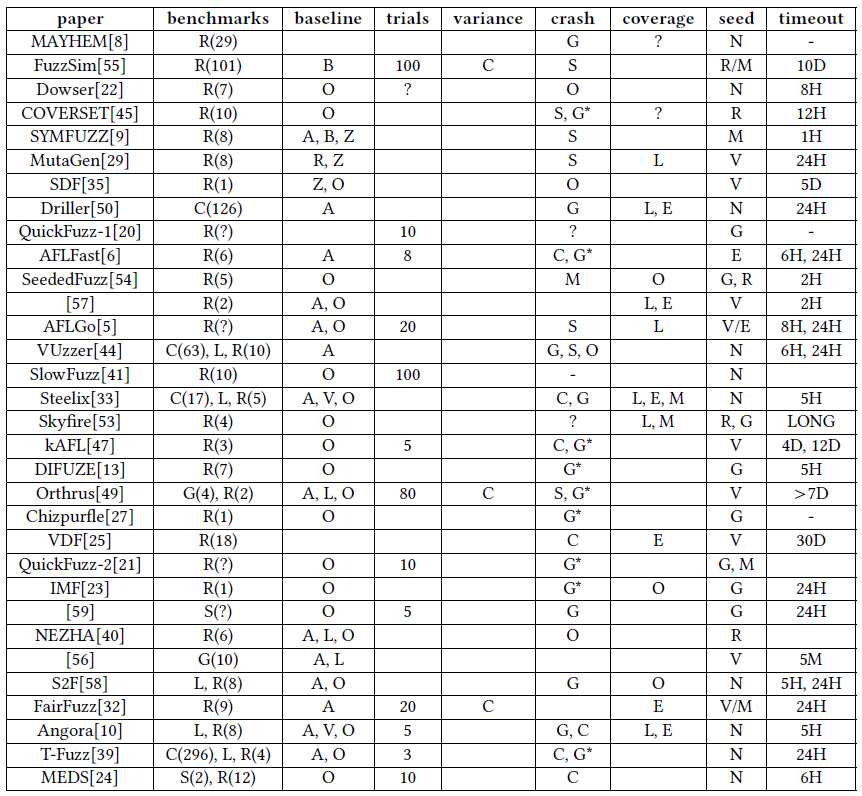
这里总结了32篇论文评价时的相关信息。
这里通过文章的主题将这些文章分类:
initSeedCorpus:
- Skyfire和Orthrus改进初始化种子选择
- QuickFuzz通过输入结构的语法生成种子输入
- DIFUZE进行前期的静态分析来识别输入的结构(?)
mutate:
- SYMFUZZ使用符号执行决定变异的种子输入的位数
- 有些fuzzer使用预定义的变异策略(如位翻转或随机代替)
- MutaGen通过代码切片使用测试程序的代码段来转换或操作输入
- SDF使用种子自身的性质指导变异
- Chizpurfle的变异器使用java语言构建器的知识辅助安卓系统服务的过程中fuzz
eval:
- Driller和MAYHEM发现某些guard条件通过暴力猜很难满足,因此使用符号执行在eval阶段绕过他们
- S2F也在eval阶段使用符号执行
- 其他工作目标加快eval阶段的速度通过修改操作系统或低层级的原语来观测执行影响
- T-Fuzz移除对于输入的检查(这些检查阻止程序达到新代码)
- MEDS进行更细粒度的运行时分析来检测error
isInteresting:
有意思的行为如:长运行时间,有差异的行为等
- Steelix和Angora进行插桩获取更细粒度的信息
- Dowser和VUzzer使用静态分析在不同程序点赋值不同的rewards来达到CFG中更深的点
choose:
- 部分工作基于输入是否到达某些区域来选择下一个候选输入
- 另一部分提出算法选择候选种子
3 综述和实验设置
评价模糊测试算法的步骤
- 选择一个baseline算法
- 选择一个有表达能力的目标程序(benchmark)
- 选择比较的度量,最理想的是找到的bug数
- 算法的参数选择,比如种子文件如何选择
- 在A和B上多次运行,进行性能上的差异显著性检验
实验设置:
fuzzers. AFL 2.43b作为baseline B,AFLFast作为advanced算法。同时使用AFL的-n选项(关闭了覆盖率跟踪),称为AFLNaive。
benchmark. nm, objdump, cxxfilt, gif2png, FFmpeg。这些程序都在最近的成果评价时用来评价工具性能。
Performance measure. unique crashes,uniqueness由AFL能覆盖的路径数决定。
platform and configuration. 每次测试跑24小时,每种测试至少跑30次。同时也尝试了多样的种子输入文件:空文件,随机选择正确类型,人工写得文件。
4 统计上的鲁棒性比较
大部分已有研究(18/32)没有提及测试的次数。这些论文可能认为随机性是均匀的,即如果测试跑了足够长时间,不同的随机会收敛,所有fuzzer会发现相同数量的crash。对于gif2png进行30次24小时的实验,AFLFast找到51个crash(中位数),AFL找到39个crash(中位数),使用Mann Whitney U-test进行显著性检验发现p-value>0.05。
讨论:最好的检验方法
两个可行的方法:
- permutation test
- bootstrap-based tests
这两个方法与Mann Whitney相比是否合适不得而知,所以本文采取Arcuri和Briand的方法。从实验结果可知方法A比B好,但是好多少不知道,所以通过比较中位数的绝对差异来隐含地回答这个问题。
5 种子选择
大多数工作(27/32)改进fuzzing loop。30/32使用非空的种子集合。
一个普遍的观点就是种子输入应该well-formed(valid)而且small。
可能初始语料库的细节并不重要,也就是说,不论种子如何初始,都能从算法的改进上体现出来。
本文使用不同种子输入测试FFmpeg,包括已有video files和randomly-generated videos。
总结来说,fuzzers在同个程序上针对不同输入的性能表现各不同。本文建议应该更谨慎地考虑,应该使用各类输入评价fuzzer的算法。论文应该写明种子输入如何收集,且最好给出实验用到的种子输入。而且empty seed应该考虑到,因为这是最简单的输入,可以被任意系统使用。
6 超时
比较常用的是24小时(10/32),和5或6小时(7/32)。6/32超过一天。
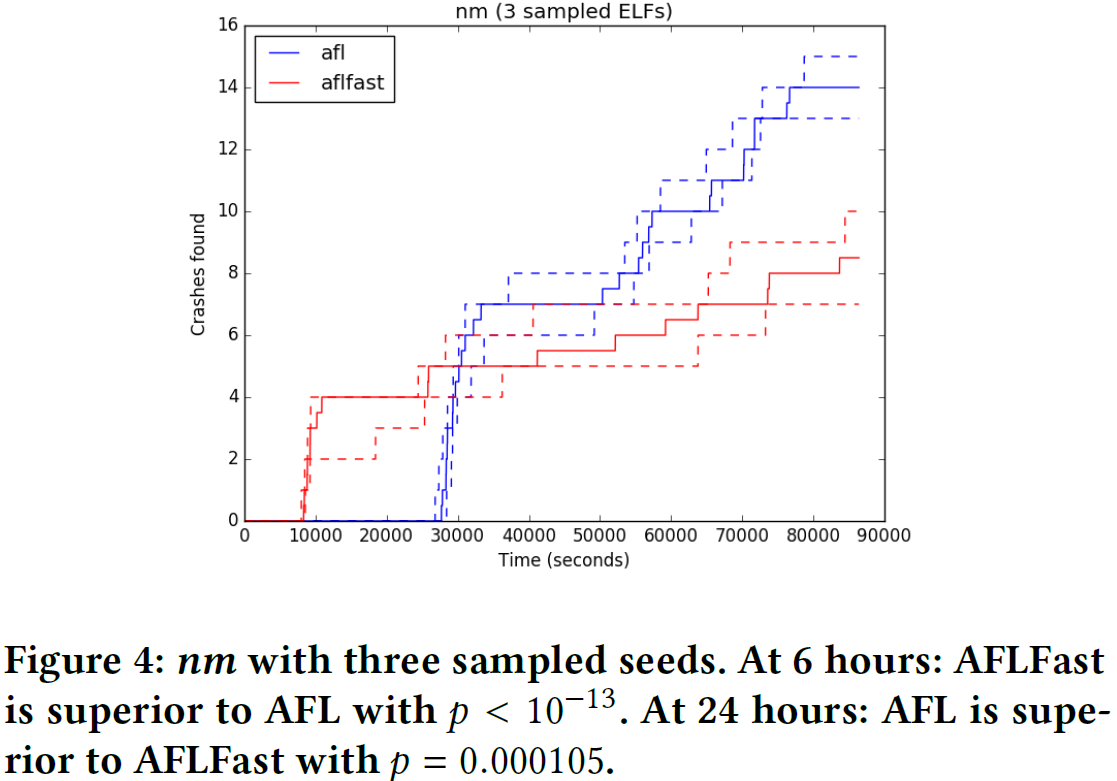
而且不同超时设置会影响实验的结果,如上图。timeout=6h时,AFL没找到crash但是AFLFast找到4个,差异是显著的;然而若timeout=24h,AFL找到14个crash而AFLFast只找到8个,这个差异也是显著的。
较短的timeout更符合实际场景。
讨论:也可以计算AUC作为报告找bug能力的度量。但是如果一个fuzzer A一开始就发现5个crash,另一个fuzzer B在最后才发现了10个crash,直觉来说B的找bug能力大于A,但是AUC较小,所以AUC度量不适用于基于时间绘图。
7 表现/性能度量
7.1 Ground Truth: Bugs Found
能找到bug是检验fuzzers性能的第一标准!
7.2 AFL覆盖率简况
7.3 Stack hashes
7.4 代码覆盖
一句话,代码覆盖率作为第二度量是讲得通的,但是最主要的评价指标还是找到的bug数(distinct bugs)。
8 目标程序
这里涉及benchmark选择的问题。
主要分为两类:
- 真实程序和人工程序(或bug)
- 手动选择的程序,人工注入bug
8.1 真实程序
使用真实程序作为benchmark的问题:
- 只使用了很少的目标程序,没有明确说明代表性。很难泛化到其他程序,7个真实项目太少了
- 在这些文章中很少有论文用到相同的目标程序(版本也相同)
Google Fuzzer Suite比较好地解决了这个问题:
- 使用了25个程序,包括已有bug
- 设计用作一类回归测试
8.2 人工程序
有时不关心特定的程序集合,而是程序中反模式的有代表性的集合。
有两个著名的suite:CGC和LAVA-M
8.3 面向一个Fuzzing Benchmark Suite
- suite包含的程序应该能够说明bug在什么是否发现的?是合成引入的还是就版本已有bug?
- suite应该足够大,能够很好表达目标程序群体的特征
- 需要构建测试方法防止overfitting(为了找更多bug而强行硬编码规则之类的?)
9 结论和未来工作
已有工作:
- 没有多次执行,没有进行性能提升的显著性检验
- 很有工作没有通过统计distinct bugs评价fuzzer的性能,而是和AFL一样使用unique crashes
- 很多工作只有很短的timeout,缺少合理的理由
- 许多工作没有认真考虑种子输入的影响
- 这些工作选择了不同的目标程序,很难比较不同工具或算法间的性能
本文建议,模糊测试效果评价应该包含以下元素:
- 多次试验,进行统计测试
- 大量包含已知bug的目标程序
- 从已知bug的方面度量性能,而不是基于AFL的启发式度量
- 全面考虑各类种子输入,包括空输入
timeout≥24h
未来工作的三条线:
- benchmark
- 在实际fuzzign结果的基础上考虑crash去重方法
- 探索改进新的基于observation的fuzzing算法